Sdc Overview
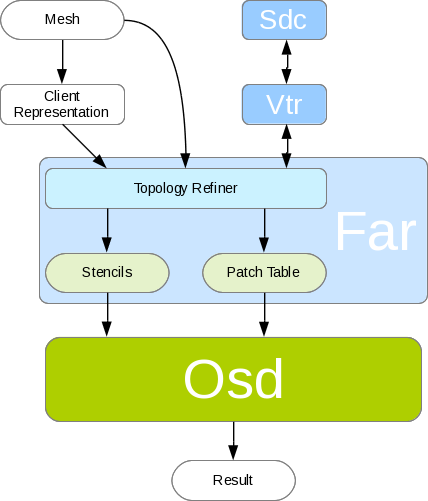
Subdivision Core (Sdc)
Sdc is the lowest level layer in OpenSubdiv. Its intent is to separate the core subdivision details from any particular representation of a mesh (it was previously bound to Hbr) to facilate other classes both internal and external to OpenSubdiv generating consistent results.
The functionality can be divided roughly into three sections:
- types, traits and options for the supported subdivision schemes
- computations required to support semi-sharp creasing
- computing mask weights for subdivided vertices for all schemes
Overall the approach taken was to extract the functionality at as low a level as possible. In some cases they are not far from being simple global functions. The intent was to start at a low level and build any higher level functionality as needed. What exists now is functional for ongoing development and anticipated needs within OpenSubdiv for the near future.
Its also worth noting that the intent of Sdc is to provide the building blocks for OpenSubdiv and its clients to efficiently process the specific set of subdivision schemes that are supported. It is not intended to be a general framework for defining customized subdivision schemes.
Alpha Issues
Warnings of change:
- note change in creasing method from "Normal" to "Uniform" and related use of "Uniform"
- all boundary interpolation choices in Sdc::Options are subject to change
Other changes under consideration:
- <MASK> face-weights to support face-centers and/or original vertices
- merging Sdc::TypeTraits<T> into Sdc::Scheme<T> as static methods
- static initialization of creasing constants (for smooth and infinitely sharp)
- how to document template paremeter interfaces, e.g. <MASK>, <FACE>, etc.?
Types, Traits and Options
The most basic type is the enum Sdc::Type that identifies the fixed set of subdivision schemes supported by OpenSubdiv: Bilinear, Catmark and Loop. With this alone, we intend to avoid all dynamic casting issues related to the scheme by simply adding members to the associated subclasses for inspection. In addition to the type enum itself, a class defining a set of TypeTraits<Type TYPE> for each scheme is provided along with the required specializations for each scheme.
The second contribution is the collection of all variations in one place that can be applied to the subdivision schemes, i.e. the boundary interpolation rules, creasing method, edge subdivision choices, etc. The fact that these are all declared in one place alone should help clients see the full set of variations that are possible.
A simple Options struct (a set of bitfields) aggregates all of these variations into a single object (the equivalent of an integer in this case) that are passed around to other Sdc classes and/or methods and are expected to be used at a higher level both within OpenSubdiv and externally. By aggregating the options and passing them around as a group, it allows us to extend the set easily in future without the need to rewire a lot of interfaces to accomodate the new choice. Clients can enables new choices at the highest level and be assured that they will propagate to the lowest level where they are relevant.
Creasing support
Since the computations involved in the support of semi-sharp creasing are independent of the subdivision scheme, the goal in Sdc was to encapsulate all related creasing functionality in a similarly independent manner. Computations involving sharpness values are also much less dependent on topology -- there are vertices and edges with sharpness values, but knowledge of faces or boundary edges is not required -- so the complexity of topological neighborhoods required for more scheme-specific functionality is arguably not necessary here.
Creasing computations have been provided as methods defined on a Crease class that is constructed with a set of Options. Its methods typically take sharpness values as inputs and compute one or a corresponding set of new sharpness values as a result. For the "Uniform" creasing method (previously known as "Normal"), the computations may be so trivial as to question whether such an interface is worth it, but for "Chaikin" or other schemes in future that are non-trivial, the benefits should be clear. Functionality is divided between both uniform and non-uniform, so clients have some control over avoiding unnecessary overhead, e.g. non-uniform computations typically require neighboring sharpness values around a vertex, while uniform does not.
Also included as part of the Crease class is the Rule enum -- this indicates if a vertex is Smooth, Crease, Dart or Corner (referred to as the "mask" in Hbr) and is a function of the sharpness values at and around a vertex. Knowing the Rule for a vertex can accelerate mask queries, and the Rule can often be inferred based on the origin of a vertex (e.g. it originated from the middle of a face, was the child of a Smooth vertex, etc.).
Methods are defined for the Crease class to:
- subdivide edge and vertex sharpness values
- determine the Rule for a vertex based on incident sharpness values
- determine the transitional weight between two sets of sharpness values
Being all low-level and working directly on sharpness values, it is a client's responsibility to coordinate the application of any hierarchical crease edits with their computations.
Similarly, in keeping with this as a low-level interface, values are passed as primitive arrays. This follows the trend in OpenSubdiv of dealing with data of various kinds (e.g. weights, component indices, now sharpness values, etc.) in small contiguous sets of values. In most internal cases we can refer to a set of values or gather what will typically be a small number of values on the stack for temporary use.
Scheme-specific support
While the TypeTraits class provides traits for each subdivision scheme supported by OpenSubdiv (i.e. Bilinear, Catmark and Loop), the Scheme class provides methods for computing the various sets of weights used to compute new vertices resulting from subdivision. The collection of weights used to compute a single vertex at a new subdivision level is typically referred to as a "mask". The primary purpose of the Scheme class is to provide such masks in a manner both general and efficient.
Each subdivision scheme has its own values for its masks, and each are provided as specializations of the template class Scheme<Type TYPE>. The intent is to minimize the amount of code specific to each scheme.
The computation of mask weights for subdivided vertices is the most significant contribution of Sdc. The use of semi-sharp creasing with each non-linear subdivision scheme complicates what are otherwise simple masks detemined solely by the topology, and packaging that functionality to achieve both the generality and efficiency desired has been a challenge.
Mask queries are defined in the Scheme class template, which has specializations for each of the supported subdivision schemes. Mask queries are defined in terms of interfaces for two template parameters: the first defining the topological neighborhood of a vertex, and a second defining a container in which to gather the individual weights:
template <typename FACE, typename MASK> void ComputeFaceVertexMask(FACE const& faceNeighborhood, MASK& faceVertexMask, ...) const;
Each mask query is expected to call methods defined for the FACE, EDGE or VERTEX classes to obtain the information they require ; typically these methods are simple queries about the topology and associated sharpness values. Clients are free to use their own mesh representations to gather the requested information as quickly as possible, or to cache some subset as member variables for immediate inline retrieval.
In general, the set of weights for a subdivided vertex is dependent on the following:
- the topology around the parent component from which the vertex originates
- the type of subdivision Rule applicable to the parent component
- the type of subdivision Rule applicable to the new child vertex
- a transitional weight blending the effect between differing parent and child rules
This seems fairly straight-forward, until we look at some of the dependencies involved:
- the parent Rule requires the sharpness values at and around the parent component
- the child Rule requires the subdivided sharpness values at and around the new child vertex (though it can sometimes be trivially inferred from the parent)
- the transitional weight between differing rules requires all parent and child sharpness values
Clearly the sharpness values are inspected multiple times and so it pays to have them available for retrieval. Computing them on an as-needed basis may be simple for uniform creasing, but a non-uniform creasing method requires traversing topological neighborhoods, and that in addition to the computation itself can be costly.
The point here is that it is potentially unreasonable to expect to evaluate the mask weights completely independent of any other consideration. Expecting and encouraging the client to have subdivided sharpness values first, for use in more than one place, is therefore recommended.
The complexity of the general case above is also unnecessary for most vertices. Any client using Sdc typically has more information about the nature of the vertex being subdivided and much of this can be avoided -- particularly for the smooth interior case that often dominates. More on that in the details of the Scheme classes.
Given that most of the complexity has been moved into the template parameters for the mask queries, the Scheme class remains fairly simple. Like the Crease class, it is instantiated with a set of Options to avoid them cluttering the interface. It is currently little more than three methods for the mask queries for each vertex type. The set of masks may need to be extended in future to include limit masks and (potentially) masks for face-varying data sets (whose neighborhoods may vary in their definition).
The mask queries have been written in a way that greatly simplifies the specializations required for each scheme. The generic implementation for both the edge-vertex and vertex-vertex masks take care of all of the creasing logic, requiring only a small set of specific masks to be assigned for each Scheme: smooth and crease masks for an edge-vertex, and smooth, crease and corner masks for a vertex-vertex. Other than the Bilinear case, which will specialize the mask queries to trivialize them for linear interpolation, the specializations for each Scheme should only require defining this set of masks -- and with two of them common (edge-vertex crease and vertex-vertex corner) the Catmark scheme only needs to define three.
The <FACE>, <EDGE> and <VERTEX> interfaces
Mask queries require an interface to a topological neighborhood, currently labeled FACE, EDGE and VERTEX. This naming potentially implies more generality than intended as such classes are only expected to provide the methods required of the mask queries to compute its associated weights. While all methods must be defined, some may rarely be invoked, and the client has considerable flexibility in the implementation of these: they can defer some evaluations lazily until required, or be pro-active and cache information in member variables for immediate access.
An approach discussed in the past has alluded to iterator classes that clients would write to traverse their meshes. The mask queries would then be parameterized in terms of a more general and generic mesh component that would make use of more general traversal iterators. The advantage here is the iterators are written once, then traversal is left to the query and only what is necessary is gathered. The disadvantages are that clients are forced to write these to do anything, getting them correct and efficient may not be trivial (or possible in some cases), and that the same data (e.g. subdivided sharpness) may be gathered or computed multiple times for different purposes.
The other extreme was to gather everything possible required at once, but that is objectionable. The approach taken here provides a reasonable compromise between the two. The mask queries ask for exactly what they want, and the provided classes are expected to deliver it as efficiently as possible. In some cases the client may already be storing it in a more accessible form and general topological iteration can be avoided.
The information requested of these classes in the three mask queries is as follows:
- For FACE:
- the number of incident vertices
- For EDGE:
- the number of incident faces
- the sharpness value of the parent edge
- the sharpness values of the two child edges
- the number of vertices per incident face
- For VERTEX:
- the number of incident faces
- the number of incident edges
- the sharpness value of the parent vertex
- the sharpness values for each incident parent edge
- the sharpness value of the child vertex
- the sharpness values for each incident child edge
The latter should not be surprising given the dependencies noted above. There are also a few more to consider for future use, e.g. whether the EDGE or VERTEX is manifold or not. In most cases additional information can be provided to the mask queries (i.e. pre-determined Rules) and most of the child sharpness values are not necessary. The most demanding situation is a fractional crease that decays to zero -- in which case all parent and child sharpness values in the neighborhood are required to determine the proper transitional weight.
The <MASK> interface
Methods dealing with the collections of weights defining a mask are typically parameterized by a MASK template parameter that contains the weights. The set of mask weights is currently divided into vertex-weights, edge-weights and face-weights -- consistent with previous usage in OpenSubdiv and providing some useful correllation between the full set of weights and topology. The vertex-weights refer to parent vertices incident the parent component from which a vertex originated, the edge-weights the vertices opposite incident edges of the parent, and the face-weights the center of indicent parent faces. Note the latter is NOT in terms of vertices of the parent but potentially vertices in the child originating from faces of the parent. This has been done historically in OpenSubdiv but is finding less use -- particularly when it comes to providing greater support for the Loop scheme -- and is a point needing attention.
So the mask queries require the following capabilities:
- assign the number of vertex, edge and/or face weights
- retrieve the number of vertex, edge and/or face weights
- assign individual vertex, edge and/or face weights by index
- retrieve individual vertex, edge and/or face weights by index
through a set of methods required of all MASK classes. Since the maximum number of weights is typically known based on the topology, usage within Vtr, Far or Hbr is expected to simply define buffers on the stack or in pre-allocated tables to be partitioned into the three sets of weights on construction of a MASK and then populated by the mask queries.
A potentially useful side-effect of this is that the client can define their weights to be stored in either single or double-precision. With that possibility in mind, care was taken within the mask queries to make use of a declared type in the MASK interface (MASK::Weight) for intermediate calculations. Having support for double-precision masks in Sdc does enable it at higher levels in OpenSubdiv if later desired, and that support is made almost trivial with MASK being generic.
It is important to remember here that these masks are being defined consistent with existing usage within OpenSubdiv: both Hbr and the subdivision tables generated by Far. As noted above, the "face weights" correspond to the centers of incident faces, i.e. vertices on the same level as the vertex for which the mask is being computed, and not relative to vertices in the parent level as with the other sets of weights. It is true that the weights can be translated into a set in terms solely of parent vertices, but in the general case (i.e. Catmark subdivision with non-quads in the base mesh) this requires additional topological association. In general we would need N-3 weights for the N-3 vertices between the two incident edges, where N is the number of vertices of each face (typically 4 even at level 0). Perhaps such a translation method could be provided on the mask class, with an optional indication of the incident face topology for the irregular cases. The Loop scheme does not have "face weights", for a vertex-vertex mask, but for an edge-vertex mask it does require weights associated with the faces incident the edge -- either the vertex opposite the edge for each triangle, or its center (which has no other use for Loop).